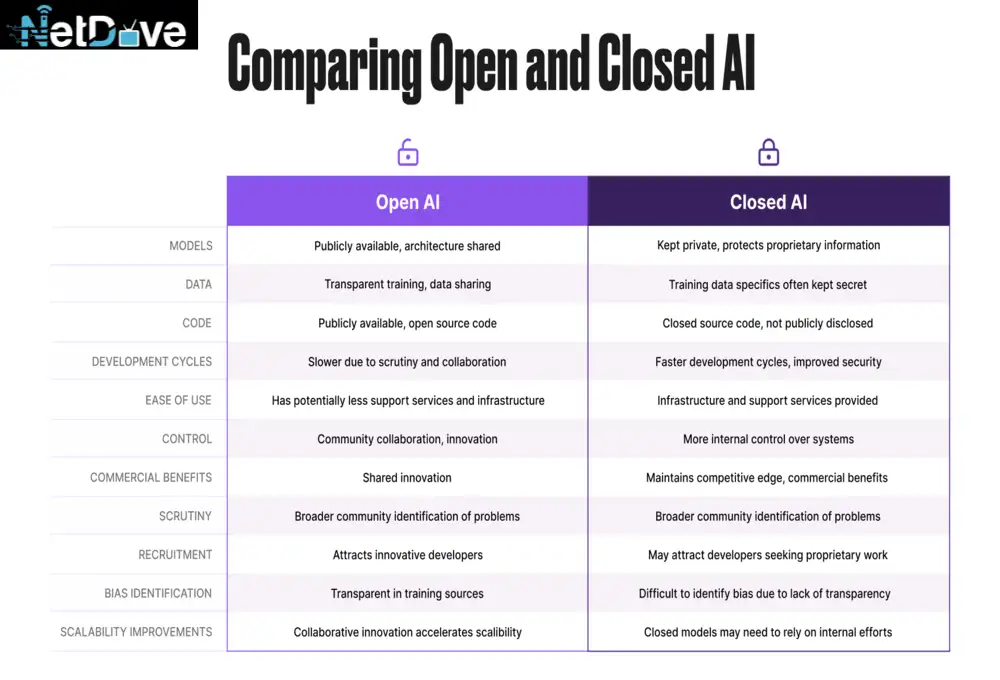
The open-source AI revolution has redefined how developers build intelligent systems. Gone are the days when machine learning innovation was locked behind closed APIs or billion-dollar infrastructure. Today, you can spin up a retrieval-augmented generation (RAG) pipeline, connect it to a vector database, and serve it through FastAPI, all using tools freely available from the open-source community.
At the heart of this transformation lies AI in Open-Source Coding – a movement where developers use frameworks like LangChain, LlamaIndex, and Hugging Face Transformers to build their own local AI stacks. Whether you’re deploying quantized models on consumer hardware with llama.cpp, or building hybrid vector search systems using Weaviate or PGVector, open-source AI gives you control, transparency, and scalability—without vendor lock-in.
Understanding the Open-Source AI Stack
Before diving into the implementation, it’s worth mapping the open-source ecosystem and how each layer interacts.
Front-End Layer
For rapid AI prototyping:
- Streamlit and Gradio let you build interactive apps directly in Python.
- For production-ready front ends, Next.js and SvelteKit shine, especially with streaming capabilities to render AI responses in real time.
Middleware and Back-End
- FastAPI offers a powerful Pythonic way to deploy APIs with built-in WebSocket support for real-time streaming.
- LangChain and LlamaIndex orchestrate multi-step workflows, chaining LLM calls, tools, and data retrieval.
- Metaflow or Prefect can handle workflow orchestration and versioning for complex pipelines.
Data Layer
This is where the intelligence meets your unique data.
- RAG systems combine retrieval with generation: instead of fine-tuning, they dynamically pull contextual documents at inference time.
- Key tools include:
- PGVector – native vector search inside PostgreSQL
- Weaviate and Milvus – purpose-built distributed vector databases
- FAISS – efficient local similarity search
- Apache Tika – document parsing for PDFs, Excel, and more
Model Layer
- Ollama or llama.cpp allows you to run quantized LLMs locally.
- Hugging Face Transformers provides APIs for thousands of open models, from Mistral and Falcon to Llama 3.
- Quantization formats like GGUF reduce memory usage and make inference viable on CPUs.
Why Retrieval-Augmented Generation (RAG) Matters
RAG has emerged as the backbone of enterprise-grade open-source AI. Instead of retraining models with every data update, RAG retrieves the most relevant information from a knowledge base and augments the model’s prompt with it.
This approach gives developers:
- Up-to-date knowledge — The model stays current with new documents.
- Explainability — Sources can be cited directly in responses.
- Security control — Data never leaves your infrastructure.
- Scalability — Add or remove documents dynamically.
Think of RAG as fine-tuning on the fly.
Architecture Overview: Open-Source RAG Stack
Here’s what a modern open-source AI stack looks like in practice:
[User Query]
↓
[FastAPI Endpoint]
↓
[LangChain Retrieval Chain]
↓
[Vector DB: PGVector / Weaviate / Milvus]
↓
[Embedding Model: SentenceTransformers / OpenAI Embeddings / Hugging Face]
↓
[LLM: Llama 3 / Mistral / Falcon / GGUF Quantized Model]
↓
[Response Streamed via WebSocket]
This architecture gives you:
- Dynamic knowledge retrieval
- Secure, local data handling
- Scalable microservice deployment
- Real-time, streaming outputs
Building a RAG Pipeline with FastAPI + PGVector
Let’s go hands-on. Below is a mini-tutorial for building a simple, open-source RAG system using FastAPI, LangChain, and PGVector.
4.1 Prerequisites
- Python 3.10+
- PostgreSQL 15+ (with PGVector extension installed)
- pip install:
pip install fastapi uvicorn langchain psycopg2-binary sentence-transformers openai
Step 1 – Connect to the Vector Database
from langchain.vectorstores import PGVector
from langchain.embeddings import HuggingFaceEmbeddings
# Initialize embedding model
embeddings = HuggingFaceEmbeddings(model_name=”sentence-transformers/all-MiniLM-L6-v2″)
# Connect to PGVector
connection_string = “postgresql+psycopg2://user:password@localhost:5432/mydb”
vector_store = PGVector(connection_string=connection_string, embedding_function=embeddings)
Step 2 – Ingest Documents
documents = [
{“id”: 1, “content”: “FastAPI is a modern Python web framework for building APIs.”},
{“id”: 2, “content”: “RAG pipelines combine retrieval and generation for LLMs.”}
]
vector_store.add_texts([doc[“content”] for doc in documents])
Step 3 – Build Retrieval-Augmented Chain
from langchain.chains import RetrievalQA
from langchain.llms import Ollama
llm = Ollama(model=”mistral”) # or llama3, local inference
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_store.as_retriever(search_kwargs={“k”: 2}),
return_source_documents=True
)
Step 4 – Expose via FastAPI Endpoint
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Query(BaseModel):
question: str
@app.post(“/ask”)
async def ask_question(query: Query):
response = qa_chain(query.question)
return {
“answer”: response[“result”],
“sources”: [doc.metadata for doc in response[“source_documents”]]
}
# Run with: uvicorn main:app –reload
That’s it. You now have a self-contained, open-source AI app capable of answering natural language questions over your documents.
Extending the Stack
Once your prototype works, you can scale up:
- Use Milvus or Weaviate for distributed vector search.
- Add a frontend (Streamlit or Next.js) for real-time chat UIs.
- Integrate observability with Prometheus or OpenTelemetry.
- Secure the API with authentication (JWT, OAuth2).
- Deploy via Docker or Kubernetes for scalable workloads.
For a full example, here’s a GitHub-ready project structure:
open-source-rag/
│
├── app/
│ ├── main.py
│ ├── retriever.py
│ ├── models/
│ ├── routes/
│
├── data/
│ ├── docs/
│ ├── embeddings/
│
├── requirements.txt
├── docker-compose.yml
└── README.md
README.md includes:
- Setup instructions
- Environment variables
- Example curl / frontend integration
License and model attribution (for compliance)
Choosing the Right Tools for Each Layer
Embeddings
Use domain-tuned models like:
- sentence-transformers/all-MiniLM-L6-v2 (general-purpose)
- bge-large-en (high-accuracy)
- intfloat/e5-base (optimized for retrieval)
Vector Databases
- PGVector – Simple, SQL-native, easy to host.
- Weaviate – Hybrid search (semantic + keyword).
- Milvus – High scalability for massive corpora.
Models
- Mistral 7B – Open, efficient, fine for summarization & Q/A.
- Llama 3 – Great open-weight base model with tool use.
- DeepSeek – Tuned for reasoning.
Use quantization (GGUF) for CPU deployment.
Frameworks
- LangChain – Orchestrates complex LLM + tool chains.
- LlamaIndex – Document loaders, splitting, and indexing.
- Metaflow – Workflow management and data versioning.
Common Pitfalls and How to Avoid Them
- Embedding Drift: Regularly re-embed documents when content updates.
- Security Leaks: Avoid embedding sensitive or PII data directly.
- Latency: Use asynchronous streaming and caching.
- Maintenance: Log model and data versions for reproducibility.
- Evaluation: Add retrieval and answer accuracy metrics.
The Future of AI in Open-Source Coding
The pace of innovation in open-source AI is staggering. Models like Mistral, Phi-3, and DeepSeek rival proprietary systems, while new vector formats and quantization algorithms make inference blazing fast on consumer hardware.
Meanwhile, frameworks like LangChain, Gradio, and FastAPI continue to democratize deployment—turning every developer into an AI product builder.
As the ecosystem evolves:
- Expect tighter integration between vector databases and RAG frameworks.
- Watch for self-hosted multimodal models (text + image + audio).
- See AI observability tools emerge as a new DevOps discipline.

Final Thoughts
AI in Open-Source Coding is more than a trend—it’s a paradigm shift. You can now build, host, and optimize advanced AI systems entirely under your control, without relying on closed platforms.
The best approach?
Start simple, use proven tools, and scale what matters.
Open-source AI empowers you to experiment, audit, and deploy confidently — one component at a time.